
When the ‘Magic Number 30’ in Sample Size goes wrong
Jan 3, 2025

Let me tell you a story
Say you, as a PM, are trying to find the average satisfaction score (X) of your product for your year-end performance report. This tiny little X will determine your life.
Of course you are not able to survey all of your users (population). You can only ask a few of them (sample), and from the sample data, you find sample X = a certain number.
You want…
The score to improve from last year’s, which was 6 (well of course it’s someone else’s work, not you 😅). And you can confidently prove that your score could never fall below 6. Otherwise, bye bye year-end bonus!
And of course, you want to spend the least money. Sample size = minimum 🙄.
So, you…
Pick the
sample size = 30, as this is the recommended minimum number for a quantitative study (amazing resource optimization skill 🥰)Survey the 30 participants, collected data and calculate the average score. Yay you’ve got
sample X=7.3(OMG! 🥳) (amazing UXR skill 😎)You immediately
t-testto calculate the certainty of your result! (amazing Data skill 😏)
Guess what, you wereable to reject the hypothesis that X=6. Hello bonus!Now you are confidently throw the result in your boss' face: “Bam! I am 95% confident that our users are very much satisfied (they rated 7.3!!!) with the product that I HAVE REVIVED FROM THE DEATH 😇”
Well, I am glad you’ve got the bonus. But I am sorry I have to prove you wrong...

The truth is, you were just incredibly lucky in this case!
Let’s say I know the real X, and I conduct the same survey with the sample size (=30) as you just did again and again 14 times over.
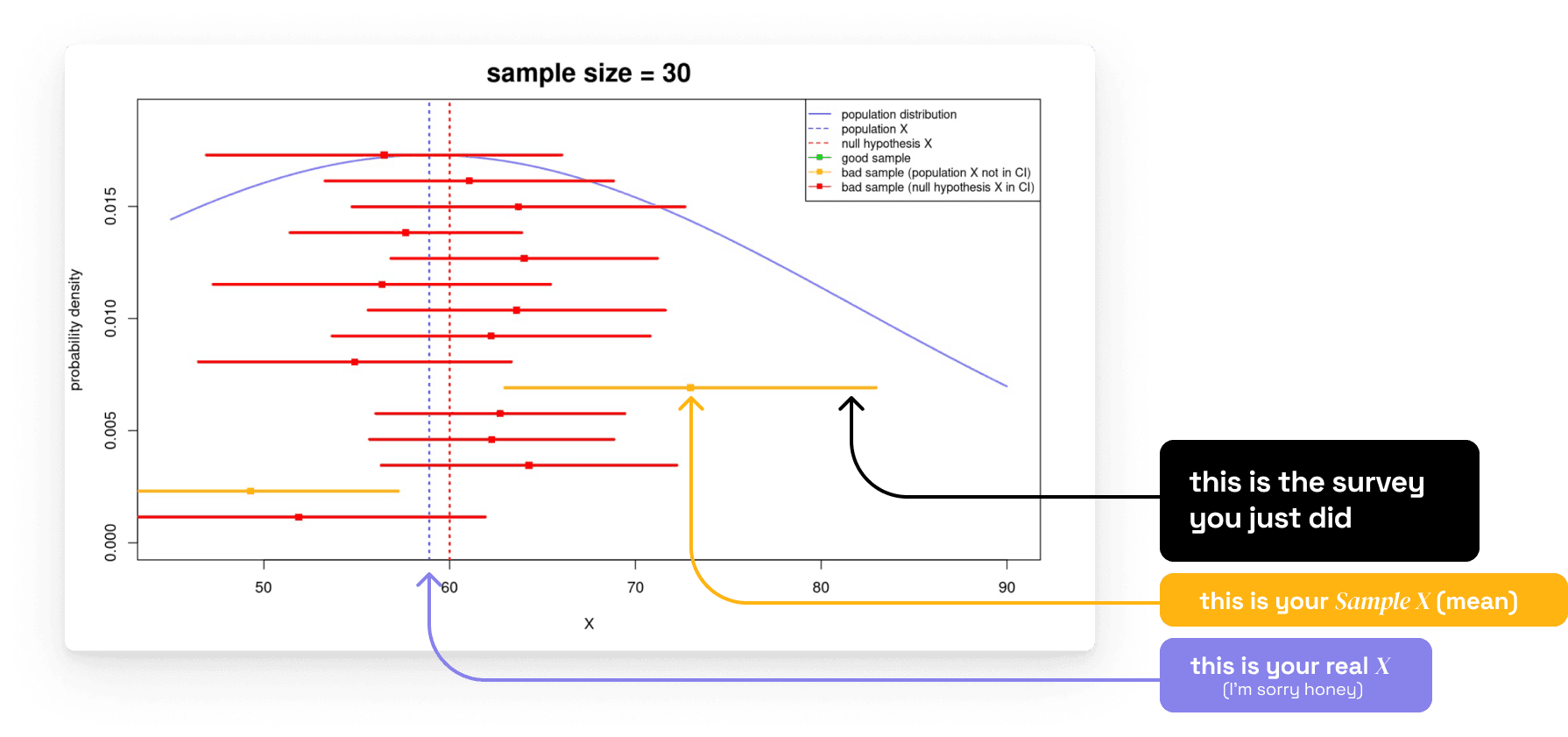
Look at all the remaining red & yellow lines, those are 14 other surveys that I just did!
What can we see here?
The line's length is the sample X's confident interval (CI). You thought simply by always doing t-test and achieving the p value <0.05 you are fine, that you have already made sure 95% that your result is credible. You thought if you re-conduct the experiment 100 times over again and calculate the corresponding 100 confidence intervals, about 95 of the CI would contain the real X (in your case – not including X=6 – The satisfaction score your users give you has to be somewhere around 6.2 to 8.3, in another word, 7.3 in average).

Well, don't be too confident! 🙂 I just did it for you 14 times only and got 13 cases that DO contain the real X. The possibility that I could not reject the null hypothesis in this case is, in fact, extremely high!!! But you, you’ve randomly got the best-wrong-result ever! 🫨
Thinking about statistical significance or p-value too binary and relying on a too small sample size is like trying to judge a book by reading only one page. Or it's like you visit Ho Chi Minh city on Tet holidays and conclude that this city is very peaceful and lovely 😁 No matter what math you use, not enough evidence is just… not enough!
Takeaways
Let's look at the below illustration I've made for you to easily understand the importance of sample size. As you can see, the bigger the sample size, the more likely you got closer to the truth, and vice versa.
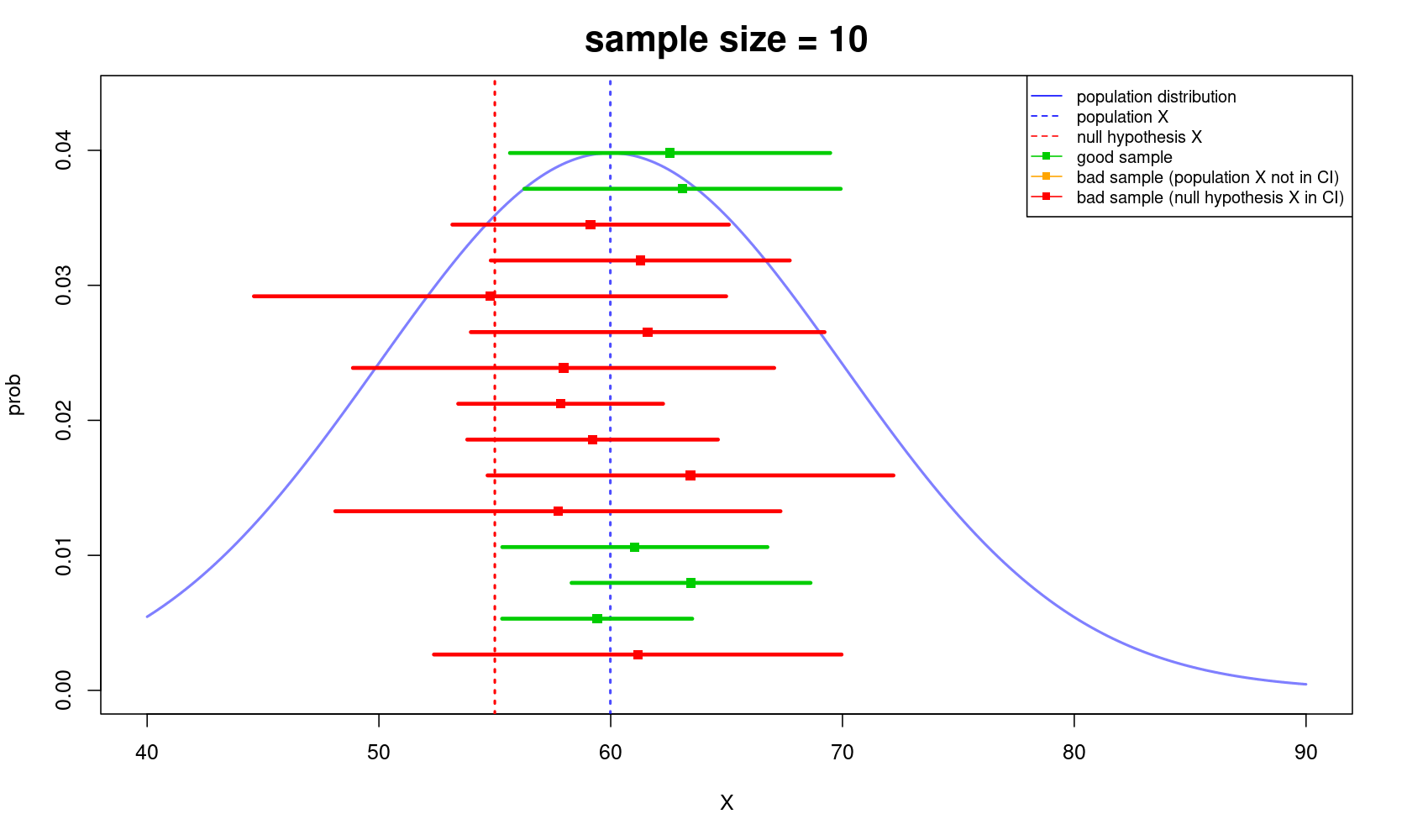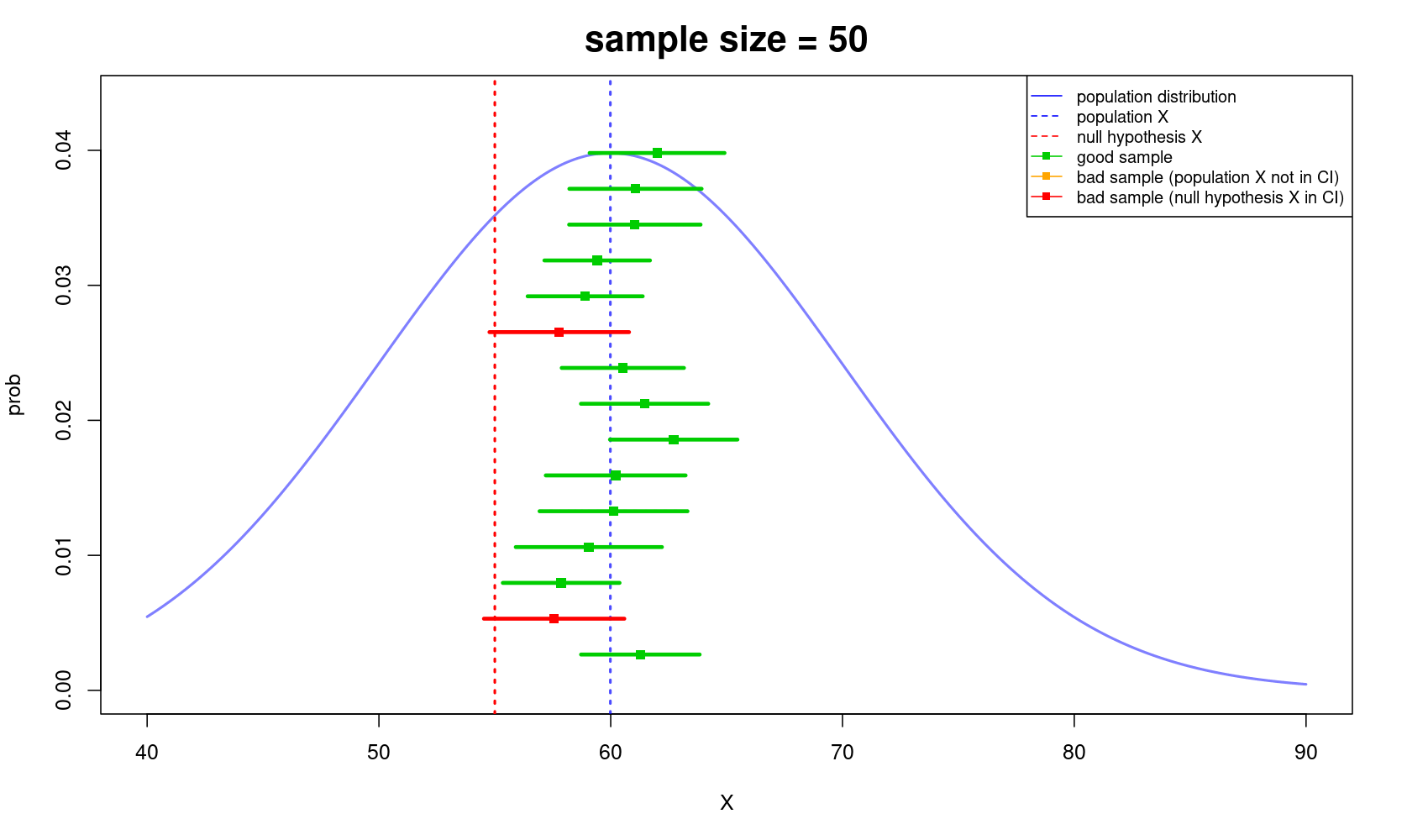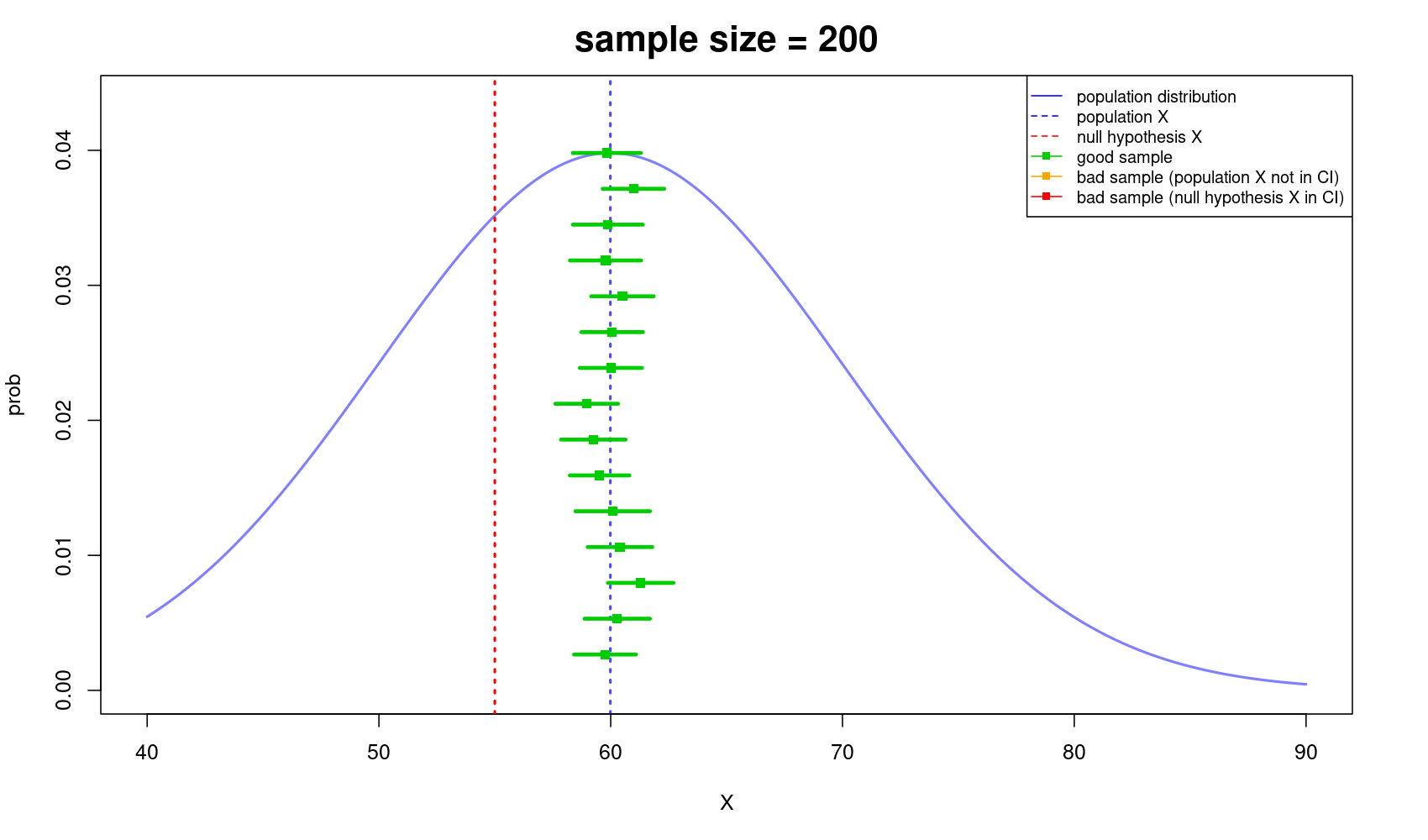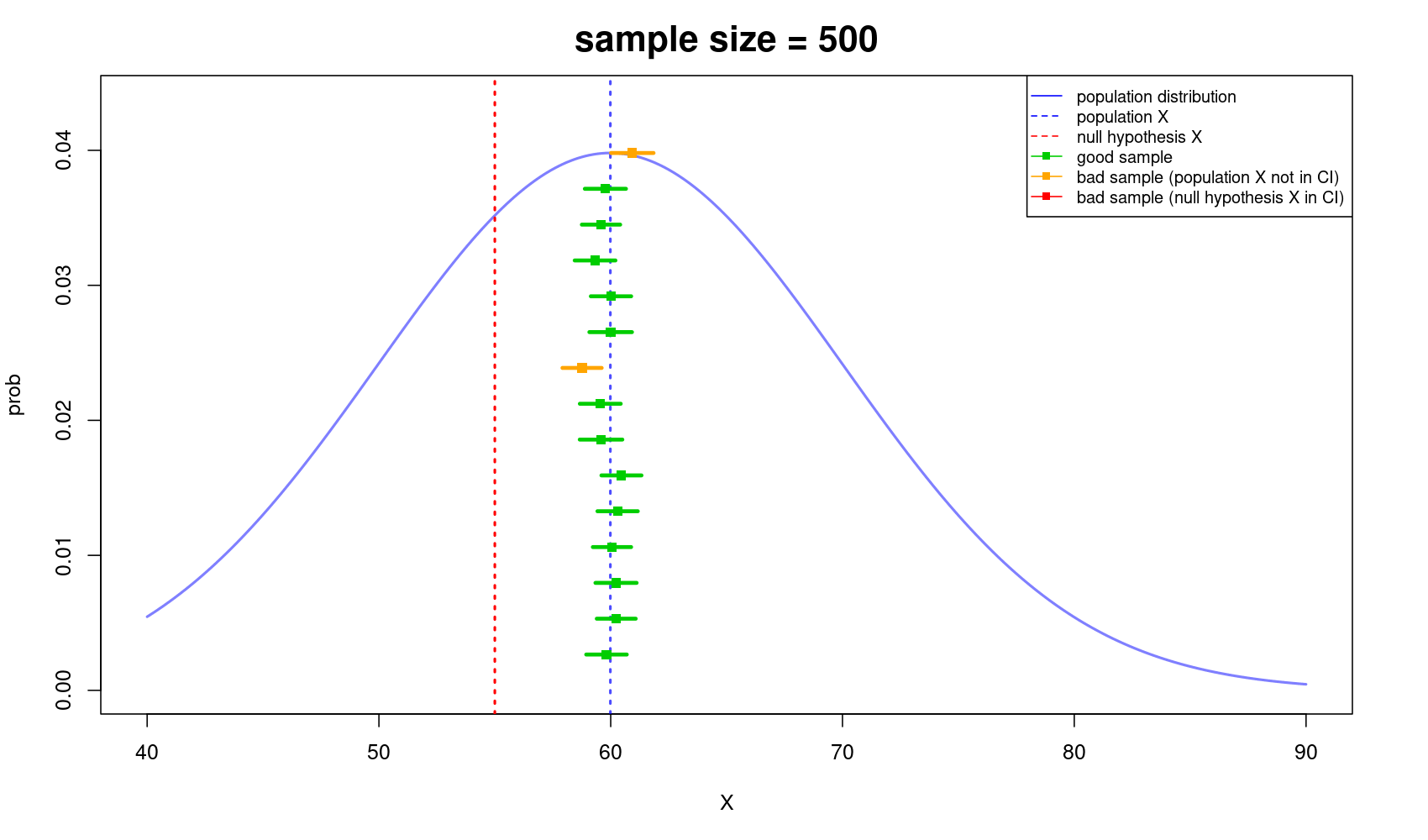
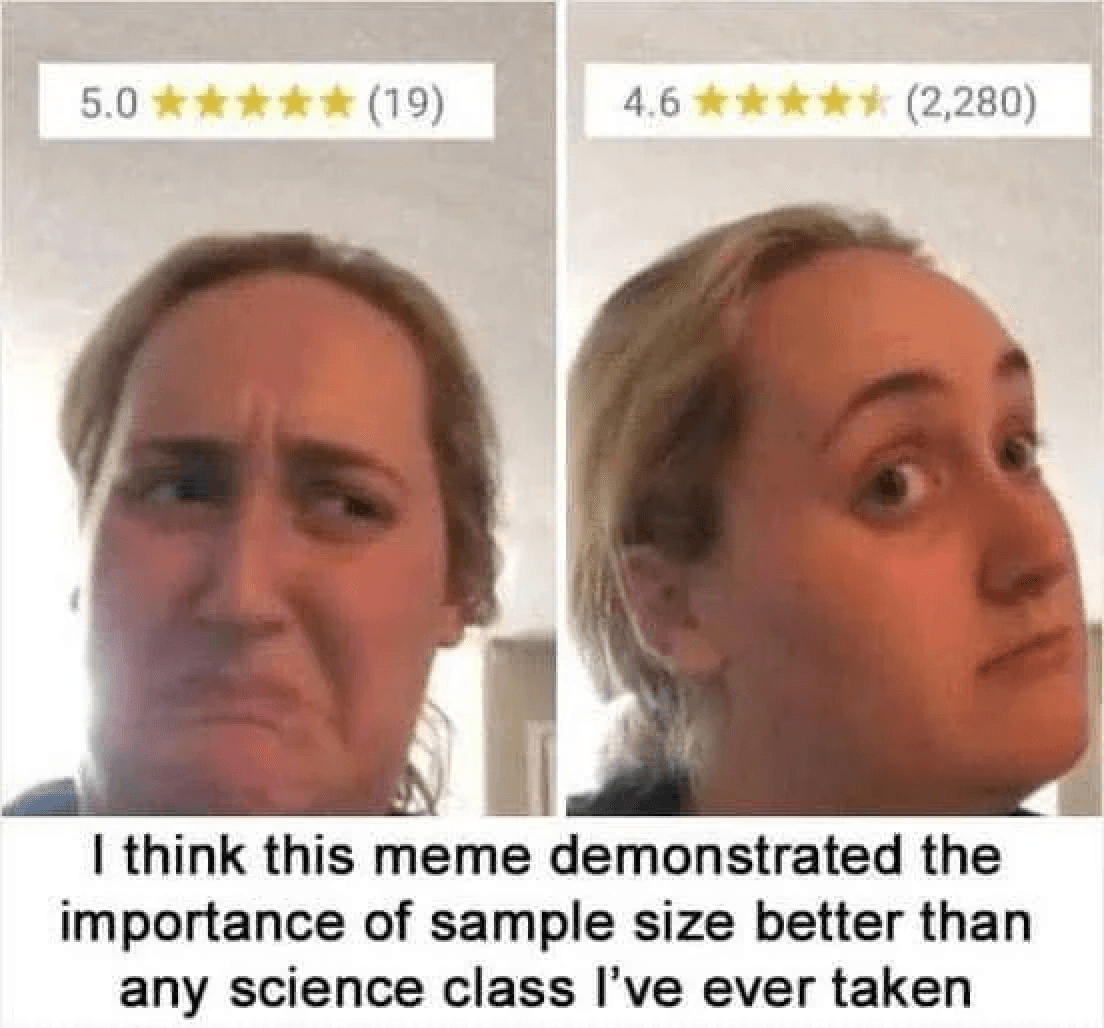
Well, or you could just look at this…
To wrap this up, as you embark on this UX Research journey, may you always remember one once said to your face…
